

AMD Hij publiceerde onlangs een patent voor het verdelen van de belasting van het scherm over meerdere GPU-chips. De gamescène is verdeeld in afzonderlijke blokken en verdeeld over houten planken om het gebruik van schaduw in games te verbeteren. Hiervoor wordt een bi-level foliecontainer gebruikt.
AMD publiceert een patent voor het implementeren van GPU-chiplets om beter gebruik te maken van shader-technologie
Een nieuw patent gepubliceerd door AMD geeft meer inzicht in wat het bedrijf de komende jaren van plan is te doen met next-level GPU- en CPU-technologie. Eind juni werd bekend dat 54 octrooiaanvragen voor publicatie waren ingediend. Het is niet bekend welke van de meer dan vijftig gepubliceerde patenten in de plannen van AMD zullen worden gebruikt. De toepassingen die in de octrooien worden besproken, illustreren de aanpak van het bedrijf in de volgende jaren.
Een app die communitylid @ETI1120 op de website opmerkte computer basispatentnummer US20220207827, bespreekt kritieke beeldgegevens in twee fasen om op een efficiënte manier ladingen weergave van de GPU over veel chips door te geven. Deze CPU werd eind vorig jaar in eerste instantie aangevraagd bij het US Patent Office.
Wanneer beeldgegevens op de GPU standaard worden gerasterd, voert de shader-eenheid, ook bekend als de ALU, een vergelijkbare taak uit en wijst een kleurnaam toe aan afzonderlijke pixels. Daarentegen worden de getextureerde polygonen die in de geselecteerde pixel in een bepaalde gamescène worden gevonden, rechtstreeks aan de pixel toegewezen. Ten slotte zal de geformuleerde taak atypische principes behouden en alleen verschillen door andere texturen die zich in verschillende pixels bevinden. Deze methode wordt SIMD genoemd, of Single Instruction – Multiple Data.

Voor de meeste huidige games zijn shaders niet de enige taak die de GPU heeft voortgebracht. Maar in plaats daarvan worden veel nabewerkingselementen opgenomen na de eerste arcering. Acties die de GPU gaat toevoegen zijn bijvoorbeeld het voorkomen van anti-aliasing, lichtafval en blokkades in de game-omgeving. Raytracing vindt echter samen met arcering plaats, waardoor een nieuwe berekeningsmethode ontstaat.
Als we het hebben over de GPU die de grafische weergave in de games van vandaag bestuurt, neemt de door de computer gegenereerde belasting exponentieel toe tot duizenden rekeneenheden.
In games op GPU’s bedraagt deze rekenbelasting op een nogal ideale manier enkele duizenden rekeneenheden. Dit verschilt van processors doordat applicaties specifiek moeten worden geschreven om meer cores toe te voegen. De CPU-planner creëert deze actie en verdeelt het werk van de GPU in meer begrijpelijke taken die worden afgehandeld door rekeneenheden, ook wel binning genoemd. De afbeelding uit het spel wordt gepresenteerd en vervolgens verdeeld in afzonderlijke blokken met een bepaald aantal pixels. Het blok wordt berekend door een subeenheid van een grafische processor, waar het wordt gesynchroniseerd en gegenereerd. Na deze procedure worden de pixels die wachten om te worden geteld, in een blok opgenomen totdat de subeenheid van de grafische kaart uiteindelijk wordt gebruikt. Er worden overwegingen gemaakt voor het arceren van rekenkracht, geheugenbandbreedte en cachegroottes.
AMD stelt in het patent dat partitioneren en samenvoegen een uitgebreide en volledige dataverbinding tussen alle elementen van de GPU vereist, wat een probleem vormt. Gegevenskoppelingen die niet op de sjabloon staan, hebben een hoge latentie, waardoor het proces langzamer gaat.
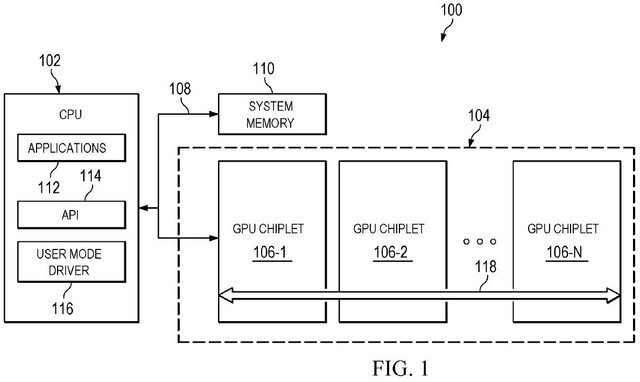
CPU’s hebben deze overgang naar chiplets moeiteloos gemaakt vanwege hun vermogen om de taak over meerdere kernen te sturen, waardoor ze zeer toegankelijk zijn voor chiplets. GPU’s bieden niet dezelfde flexibiliteit, waardoor ze vergelijkbaar zijn met een dual-core preprocessor.
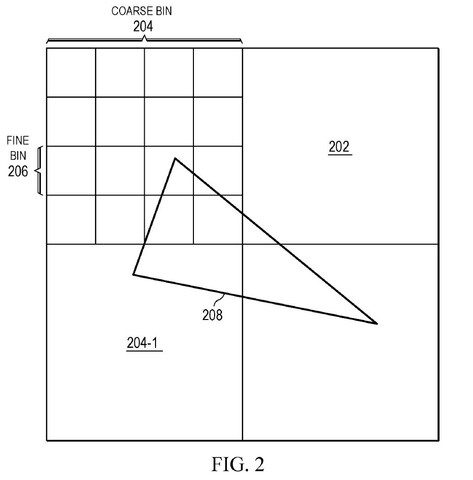
AMD erkent de noodzaak en probeert antwoorden op deze problemen te bieden door de rasterisatiepijplijn te wijzigen en taken tussen meerdere GPU’s te verzenden, vergelijkbaar met CPU’s. Dit vereist geavanceerde binning-technologie, die het bedrijf “binning binning” aanbiedt, ook wel bekend als “binning binning”.


Bij superassemblage wordt de splitsing in twee afzonderlijke fasen verwerkt in plaats van directe verwerking in pixel-voor-pixel blokken. De eerste stap is om de vergelijking te berekenen, een 3D-omgeving te nemen en een 2D-afbeelding van het origineel te maken. De fase wordt vertex shaders genoemd en is voltooid vóór rastering, en het proces is erg klein in de eerste chip van de GPU. Eenmaal klaar, begint de gamescène te vervagen, evolueert het naar gekartelde dozen en wordt het verwerkt in een enkele GPU-chip. Daarna kunnen routinematige taken zoals puntjes en nabewerking beginnen.


Het is niet bekend wanneer AMD van plan is dit nieuwe proces te gaan gebruiken en of het wordt goedgekeurd. Het geeft ons echter wel een kijkje in de toekomst van efficiëntere GPU-verwerking.
nieuwsbronnen: computer basisEn de Gratis patenten online

“Organizer. Travel Enthusiast. Explorer. Award-Winning Entrepreneur. Twitteraholic.”




More Stories
Deze 100W GaN-oplader is dun en opvouwbaar
Nu Uncharted op pauze staat, brengt Xbox een Indiana Jones-avontuur naar PS5
Android-malware steelt betaalkaartgegevens met behulp van nooit eerder vertoonde technologie